8-minute read, 2 for Overview and bold text.
Overview
In Hi-Fi speakers “quality is in the mid-range”; in investing “it’s never as good or bad as it seems”; in Buddhism “avoid extremes; follow the Middle Way.” So too, LLMs occupy a nuanced middle between hype and dashed hopes. This post reveals two axioms that recenter LLMs on a table around which managers can draft predictable ROI from LLM deployments. The Quality–Scope Decision Matrix halts the epidemic of time wasted on LLM uses that fail to deliver.
I post rarely and only when your reading most words delivers transformative value. Still, if you don’t have 8 minutes to read it all, plus 3 to grasp the Decision Matrix below, here’s the 30-second gist:
Recent AI market volatility and “Model Collapse” warnings obscure a critical reality: LLMs offer SMEs predictable ROI only if managers delegate by required quality/innovation and the project’s complexity. Introducing the Quality–Scope Decision Matrix for LLM Deployment, this post shows a Middle Way that balances transformers’ inherent averaging and memory problems with the ROI of compensatory tactics built into workflows. By distinguishing between “Adequacy Only” tasks and high risk-reward “Pro” projects, we reveal an Efficient Frontier for SMEs. This post provides a roadmap for integrating LLMs’ Ferrari engines into your corporate chassis today while steering toward the fast-approaching AGI ramp. Map small-scope deployments that pay back under three months while building expertise and components for Executive LLMs that deliver long-haul profit before and after AGI. While competitors spin their wheels, your LLM workflows chosen for dependable ROI become assets that appreciate, pay dividends, and pave your AGI on-ramp. The Quality–Scope Decision Matrix realizes DISC’s principle that “Innovation Efficiently Integrated Is Integrity Proven by Results.“
This post is not easy reading, for its two core axioms are unique to this new complex tech. Digesting the ~2 hours of linked sources will assist understanding this post, while sharpening your 360 vision. Like my prior posts, the value of this post will endure for years.
Clarifying AGI and its Birthday
Let’s leave aside whether AI stock prices and projected returns on capital show a bubble, and instead focus on business efficiencies in SMEs‘ deployment of LLMs. In contrast to SME’s, enterprise deployments are greatly augmented with dedicated compute, persistent memory, and pre-LLM automation checkpoints. In short, enterprise deployments are in a separate league, producing what looks like AGI now. However, that AGI depends on costly software augmentations and lots of pro labor. AI/LLM’s impact on employment emerges from enterprise economies of scale wherein high cost is repaid by numerous job terminations. True AGI, on the other hand, will require no such enterprise-grade augmentation.
In my September 2023 blog post, LLMs agreed with my thesis that “autonomous synergies [essentially AGI] won’t happen for 3 years, maybe 5.” Definitions of AGI writhe like a Klingon delicacy, so let’s cook it down to a sensible middle: AGI is here when LLMs can (1) autonomously perform most deskwork as competently as 75% of professionals, (2) with at most 75% of pre-LLM cost, and (3) this capability is proven by an ample variety of firms.
Recent news makes Q4 2027 to Q4 2028 the likely birthday of this AGI, within my 2023 3 to 5 years. A mere summary of my years and countless hours of R&D backing this projection would fill pages, so for this projection and for the key axioms below I provide only a few primer sources. The first two sources below are required for anyone navigating the emergent LLM workforce:
- The super-viral article, Something Big Is Happening, 2/9/26, 15-minute read time.
- The January ’26 Phase Change, early February 2026, 24-minute video.
Sure, good AI pros can make agentic workflows that perform close enough to top pro quality today, but the goal, or threat, is that any manager could speak objectives to an LLM–just like to a human pro–so that with minimal supervision the LLM delivers. One of countless proofs that we’re far from that goal is that my firm’s well-tuned LLMs could not handle autonomous production of the core Quality–Scope Decision Matrix below. Its unique twin axioms operate by an algorithmic logic that mere pattern matching could not represent without my handholding. I surmise that such failures greatly outnumber successes.
Understanding AGI for SMEs
Current and future ROI from LLMs requires (1) discerning two kinds of deployment and two levels of quality needed, then (2) applying to those twin axioms an understanding of (a) the memory problem at the core of LLM tech and (b) LLMs’ convincing use of averaging to cover their lack of deductive reasoning. We’ll examine each of these parts, and then put them together in a decision matrix you can use, with your LLM’s help, to choose successful LLM deployments.
The Averaging and Memory Problems
Several hours of studying how transformers work can reveal that the averaging and memory weaknesses are inherent and inextricable, although they can be mostly overcome by adding low-ish cost tactics to LLM workflows. (Here’s an excellent primer: Model Collapse Ends AI Hype.)
- LLMs work by Averaging Pro Knowledge: LLMs cannot use deductive reasoning reliably in order to apply professional concepts to unique situations. While there are compelling hints that LLMs can abstract from a pattern in one domain something like a principle that is later applied to a new problem (innovation), that evidence is anecdotal and analogical, not systematic. And rare occurrences are far from dependable. Although average pro knowledge is often “good enough for government work,” often it isn’t.
- Noteworthy but beyond our focus here is the fascinating theory that the quality of LLMs’ output will decline as it averages ever more public content that itself consists of prior LLM averaging. Read LLMs’ terms of service closely, for one solution to this “dead internet” of mere averages is using clients’ valuable documents to inject new life.
- Insufficient Medium- and Long-term Memory. The “hyperscalers,” like ChatGPT and Gemini, purport project and account memory, but it’s spotty, omitting crucial points and work milestones that a human pro must and would remember. LLMs’ ability to replace middle and upper managers depends on human-like memory, for which semi-automatic solutions exist now. These solutions put the capstone on the essential structure of context (data, brand briefs, goals, etc,) by which a pro is informed. This guru explains beautifully: My AI Workflow. My firm has been using a semi-simple system integrated with Google Drive. Memory that evolves as months of work shift priorities is a must, yet such memory is porous and fleeting in current LLMs.
AGI depends on fixing those two crippling weaknesses.
The Two Levels of Quality
- Adequacy Only: Often managers (and home users) can be fully satisfied by mere adequacy, and don’t need top pro quality. For example, finding weaknesses in a lease or car insurance contract, troubleshooting a network outage, guidance in routine legal procedures, a summary of current treatment options--think of how often a merely average pro’s guidance is all you need. LLM’s deliver stellar value in these areas.
- A Top 25%+ Pro Required: Complex high cost/risk and high benefit/profit projects exceed what LLMs can deliver dependably prior to AGI. Shoving aside the jubilant mob of YouTubers, and reading trenchant studies on LLMs’ fundamental lack of deductive reasoning, we learn that such quality is not available now and may never be within transformer (Nvidia) chips’ 3-5 year depreciation cycle. Sound studies reveal that the apparent reasoning steps in Chain of Thought (CoT) methods are actually derivative statistical constructs, not algorithmic logic that innovates like top human pros.
The Two Kinds of Deployment
- Customized LLMs (like GEMs and “Projects”) that meet small-scope, one-off needs: Examples include paralegal work, simple contract reviews, complex yet common purchase decisions, and intro training. For these tasks, LLMs typically repay all money and time invested within 3 months and often immediately.
- Customized LLMs that handle all parts of major projects: Examples include website design/build, year-end CPA filings, and automated R&D systems. Don’t believe the YouTubers with contorted faces who declare this is doable now (but only if you buy their package). ROI for this kind of deployment exceeds 3 months, often 1 year.
- BTW, I bet a YouTube channel focusing on all the things LLMs cannot do would prosper)
The Quality–Scope Decision Matrix for LLM Deployment
Like the Eisenhower or Urgent vs. Important matrices, here the above axioms are distilled into a matrix for choosing what to delegate to an LLM “employee.”
Pointers:
- A few minutes grasping this decision matrix will save tons of time deploying LLMs.
- When AGI arrives, widespread business integration will take an additional 1 to 3 years. Firms that have deployed LLMs prior to AGI will be primed to benefit, realizing huge competitive advantage.
- The bigger the firm, the greater the percent of projects that tend to appear in quadrants 3 and 4.
- You should add this whole post and its matrix to your LLM’s Knowledge Base to help discover your unique “Efficient Frontier” in LLM deployment. (I thought about vibe-coding an app that helps people use this tool, but as of January 2026, LLMs properly setup can ensure effective use.)
- This Matrix assumes competent prompting and context (Knowledge Base & Custom Instructions).
- You’ll know you understand this matrix if you can see why the arrival of AGI will shift more work at more kinds and sizes of firms into quadrants 3 and 4.
The Quality-Scope Decision Matrix, for LLM Deployment
Left axis: Extent of Innovation & Quality,” increases downward.
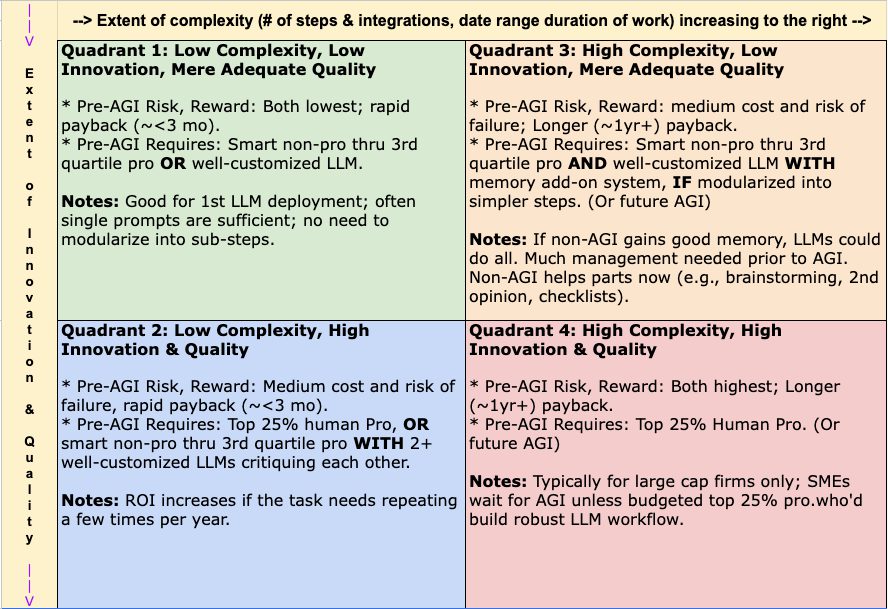
Contact DISC for a free Excel or Sheet version of this matrix. Your current LLM can situate projects within the matrix quadrants to prioritize by ROI.
A Long View: ASI vs (Expensive) AGI
Hype supporting massive LLM investments seems to suppress YouTubes by the world’s top AI pioneers explaining why current LLM architecture can’t achieve Artificial Super-Intelligence (ASI). The upshot is that LLMs’ language or pixel pattern matching is very far from evolution’s base programming language whereby physical space plus time is rendered into accurate predictive models. Musk may indeed be first to achieve ASI because of his real-world data and systems via cars and robots. LLM pioneers pursue various non-language models. Yes, LLMs will achieve Artificial General Intelligence (AGI) by the CPU-intensive brute-forcing of language patterns into a simulation of intelligence, but that’s a far cry from ASI.
Appendix: The Few Crucial Guidelines LLMs Won’t Tell You
LLMs are unlikely to give you a few important guidelines, some of which are listed below. LLMs are superb for customizing free training programs, which means that anybody selling ongoing AI/LLM training lacks smarts or integrity or both. However, recall that LLMs’ averaging of pro content tends to omit rare excellence, so that such training programs will likely omit these crucial guidelines. Furthermore, financial incentives across the web may suppress guidelines that could reduce revenue for (a) hyperscalers like Google’s Gemini and (b) channels that sell advertising to the Magnificent Seven, to their legion subdivisions and partners, and to other large firms.
I use DISC’s standard P1 though P5 to assign priority from highest to near negligible.
- P1 – It’s crucial to distinguish LLM IQ (benchmark scores) from effective workflow integrations. As one LLM guru said 2 years ago, even an old 2023 model is like giving a Ferrari engine to a 1920s car maker: driveable benefits require integrating the power within the corporate chassis–its workflow, offerings, and marketing. For an excellent elucidation of integration bottlenecks, see this 2/27/26 video (32 minutes). Your take-away: With LLM IQs now high, your building context and evolving memory into your LLM executives is the primary determinant of successful deployment.
- P2 – Your LLM’s Custom Instructions should require output that contains a “Contrarian Review” toward the end. This helps prevent hallucinations and LLMs’ tendency to elaborate on one pattern at the expense of valid contrary perspectives. This final contrarian section will often reveal crucial weaknesses in the prior output. (Remember as well that often such weaknesses are caused by prompts that unintentionally stack the deck in favor of the prompter’s bias.) DISC’s LLM wrote this example Contrarian Review of this whole blog post:
- “Your framework may underestimate how rapidly hybrid systems could narrow the gap between ‘average pro’ and ‘top-25% pro.’ Standalone LLMs may remain insufficient, yet increasingly automated workflows could approximate high-level professional performance prior to AGI.”
- P2 – Optimizing your Cloud for AI/LLMs (as in DISC’s OCA package) remains your foundational step one. You’ll discover (or your LLM will tell you) why, but in short, smart management of memory and workflow is enabled by a well-organized file system.
- P2 – Optimizing your use of the Quality-Scope Decision Matrix and all phases of LLM deployments will benefit greatly from sharing experiences with peers, even with competitors. For example, the principle that open-source sharing lifts all boats underlies DISC’s SALI, which are Seminars for the Agency LLM Initiative” (ALI) and for ALI partners like LivingLocal413.org.
- See The Few Crucial Guidelines LLMs Won’t Tell You for the complete list.
Sources and a Footnote
- This post was entirely written by DISC’s CEO Rob Laporte, though proofreading and some fact checking was done by two of DISC’s custom LLMs.
- Footnote: Attesting to LLM’s lack of reasoning from first principles, neither ChatGPT nor Gemini could write well the Overview’s gist. I surmise that the precise orchestration of axioms within the Quality-Scope Matrix is washed out by LLMs’ averaging of many apparently similar matrices that are actually quite different from this Matrix. It’s a perfect example of the current–and perhaps intrinsic and irreparable–limitations in current transformer architecture. Per the “Dead Internet Theory,” this failure to summarize may foreshadow LLMs’ drift towards the roadside ditch of mediocrity.
- The videos and articles linked above are among the very best I’ve encountered–highly recommended. In some links to videos I replace zinger titles with mere description.
- DISC’s prior 6-post series on LLMs for business remain valid and sound today, testifying to my semi-idiot, semi savant capabilities.
Eager to deploy? Learn how in the next post on an AI OS that really works –>

